9.2-目标函数:定义最优策略
在策略梯度方法中,用于定义最优策略的目标函数有以下两种。
目标函数1:平均状态值(Average state value)¶
第一个常见的目标函数是平均状态值。其定义为
其中\(d(s)\)表示状态\(s\)的权重。它满足对于任意\(s \in S\),有\(d(s) \geq0\)且\(\sum_{s\in S} d(s) =1\)。因此,权重\(d(s)\)也可以解释为状态\(s\)的概率分布。那么该目标函数可以重写为
\(\bar{v}_\pi\)是所有状态值的加权平均,不同的\(\theta\)将导致不同的\(\bar{v}_\pi\)值,我们的任务为找到一个最优策略(最优的\(\theta\))来最大化\(\bar{v}_\pi\)。
如何选择\(d\)的概率分布?有如下两种常见情况。
-
第一种情况,\(d\)与策略\(\pi\)无关。此时该目标函数对策略参数求梯度不需要考虑\(d\),在这个情况下,我们用\(d_0\)来代替\(d\),用\(\bar{v}^0_\pi\)代替\(\bar{v}_\pi\),以表明该概率分布于策略无关。
例如,如果我们认为所有状态的重要性相同,可以选择\(d_0(s) =1/|\mathcal{S}|\),如果我们仅关注特定状态\(s_0\)时(例如智能体总是从\(s_0\)出发),那么可以设计
\[d_0(s_0)=1,\quad d_0(s\neq s_0)=0.\]此时\(\bar{v}_\pi=v_\pi(s_0)\),优化该目标函数就是优化从\(s_0\)出发的回报期望值。
-
第二种情况,\(d\)与策略\(\pi\)。此时常见的选择\(d\)设为\(d_\pi\),即在\(\pi\)下的稳态分布。如何理解这一选择呢?平稳分布反映了马尔可夫决策过程的长期行为。如果一个状态在长期内经常被访问,则其重要性高,应该拥有更高的权重;如果一个状态很少被访问,则其重要性较低,应赋予较小权重。
\(d^\pi\)的一个基本性质是\(d_\pi^TP_\pi=d_\pi^T,\)其中\(P_\pi\)为状态转移概率矩阵。关于平稳分布的更多信息可参阅Box \(8.1\)。
接下来我们介绍\(\bar{v}_\pi\)的另外两种重要等价表达式。特别是第一个表达式,大家在阅读文献时会经常遇到。
-
等价表达式1:假设智能体根据给定策略 \(\pi(\theta)\)收集了一个奖励序列 \(\{R_{t+1}\}_{t=0}^\infty\)。大家会经常在文献中看到如下目标函数:
\[J(\theta)=\lim_{n\to\infty}\mathbb{E}\left[\sum_{t=0}^n\gamma^tR_{t+1}\right]=\mathbb{E}\left[\sum_{t=0}^\infty\gamma^tR_{t+1}\right].\tag{9.1}\]虽然这个目标函数初看可能不易理解。但实际上它就是平均状态值\(\bar{v}_\pi\),这是因为
\[\begin{aligned}\mathbb{E}\left[\sum_{t=0}^{\infty}\gamma^{t}R_{t+1}\right]&=\sum_{s\in\mathcal{S}}d(s)\mathbb{E}\left[\sum_{t=0}^{\infty}\gamma^{t}R_{t+1}|S_{0}=s\right]\\&=\sum_{s\in\mathcal{S}}d(s)v_{\pi}(s)\\&=\bar{v}_{\pi}.\end{aligned}\]上式中的第一个等式由全期望定律(law of total expectation)得出;第二个等号则基于状态值的定义。
-
等价表达式2:目标函数\(\bar{v}_\pi\)也可以表示为两个向量的内积。令
\[v_{\pi}=[\ldots,v_{\pi}(s),\ldots]^{T}\in\mathbb{R}^{|\mathcal{S}|},d=[\ldots,d(s),\ldots]^{T}\in\mathbb{R}^{|\mathcal{S}|}.\]于是我们得到
\[\bar{v}_\pi=d^Tv_\pi.\]该表达式在分析其梯度时将十分有用。
指标2:平均奖励(Average reward)¶
第二个指标是平均奖励(average reward)[2,64,65],其定义为
其中\(d_\pi\)为平稳分布,且
这是从状态\(s\)出发的即时奖励的期望值。其中,\(r(s, a) = \mathbb{E}[R|s, a] = \sum rp(r|s, a)\)。
接下来我们给出\(\bar{r}_\pi\)的另外两种重要等价表达式。特别注意第一个表达式。
-
等价表达式1:假设智能体遵循给定策略\(\pi(\theta)\)收集到一个奖励序列\(\{R_{t+1}\}_{t=0}^\infty\)。大家可能经常在文献中看到如下目标函数:
\[J(\theta)=\lim_{n\to\infty}\frac{1}{n}\mathbb{E}\left[\sum_{t=0}^{n-1}R_{t+1}\right].\tag{9.4}\]虽然这个目标函数乍看很复杂,特别是其中还涉及到求极限,但它实际上就是平均奖励\(\bar{r}_\pi\),这是因为:
\[\lim_{n\to\infty}\frac{1}{n}\mathbb{E}\left[\sum_{t=0}^{n-1}R_{t+1}\right]=\sum_{s\in\mathcal{S}}d_{\pi}(s)r_{\pi}(s)=\bar{r}_{\pi}.\tag{9.5}\]\((9.5)\)式的证明见Box 9.1。
-
等价表达式2:平均奖励\(\bar{r}_\pi\)也可表示为两个向量的内积。令
\[r_{\pi}=[\ldots,r_{\pi}(s),\ldots]^{T}\in\mathbb{R}^{|S|},d_{\pi}=[\ldots,d_{\pi}(s),\ldots]^{T}\in\mathbb{R}^{|S|},\]其中\(r_\pi(s)\)由式\((9.3)\)定义。显然,
\[\bar{r}_\pi=\sum_{s\in\mathcal{S}}d_\pi(s)r_\pi(s)=d_\pi^Tr_\pi.\]该表达式在推导其梯度时将非常有用。
小结¶
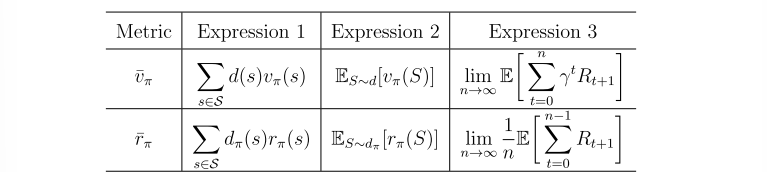
表\(9.2\):\(\bar{v}_\pi\)与\(\bar{r}_\pi\)不同但等价表达式的汇总。
截至目前,我们已经介绍了两种目标函数:\(\bar{v}_\pi\)和\(\bar{r}_\pi\)。每种目标函数都有几种形式不同但等价的表达式,见表\(9.2\)。我们有时用\(\bar{v}_\pi\)特指状态分布为平稳分布\(d_\pi\)的情形,而\(\bar{v}^0_\pi\)表示\(d_0\)与\(\pi\)无关的的情形。关于这些目标函数的补充说明如下:
-
第一,所有这些目标函数都是\(\pi\)的函数。由于\(\pi\)是由 \(\theta\)参数化,这些目标函数也是\(\theta\)的函数。换言之,不同的\(\theta\)值会生成不同的目标函数值。因此,我们可以通过搜索参数\(\theta\)的最优值来最大化这些目标函数。这正是策略梯度方法的基本思想。
-
在折扣因子\(\gamma<1\)的情况下,两个指标\(\bar{v}_\pi\)与\(\bar{r}_\pi\)是等价的(而非相等)的。这是因为:
\[\bar{r}_{\pi}=(1-\gamma)\bar{v}_{\pi}.\]上述方程表明这两个指标可以同时被最大化。因此我们不需要纠结该选择哪个目标函数。该方程的证明将在后续引理9.1中给出。
Note
\(\bar{r}_\pi\)似乎看起来更加短视,因为他只考虑即时奖励,但是\(\bar{v}_\pi\)考虑整个步骤的总回报。