8.2-基于值函数的时序差分算法:状态值估计
本节将阐述如何将值函数与时序差分(temporal difference, TD)方法相结合,实现第一个给定策略的状态值的估计。该算法将在\(8.3\)节进一步扩展至行动值与最优策略的学习。
本节包含多个小节和内容。在正式开始之前,有必要先简要梳理一下这些内容。
-
值函数法实际上将状态值估计问题描述为一个优化问题。这个优化问题的目标函数在第\(8.2.1\)节介绍。用于优化该目标函数的TD算法将在第\(8.2.2\)节中介绍。
-
为应用TD算法,我们需要选择合适的特征向量。\(8.2.3\)节将讨论该问题。
-
\(8.2.4\)节通过示例,展示基于值函数的TD算法的效果,以及不同特征向量的影响。
-
第\(8.2.5\)节将讨论值函数法的理论性质。该小节包含大量数学推导,读者可根据兴趣选择性阅读。
8.2.1 目标函数¶
设\(v_\pi(s)\)与\(\hat{v}(s, w)\)分别表示状态\(s \in S\)的真实状态值和估计状态值。我们的任务是找到最优参数\(w\),从而使得\(\hat{v}(s, w)\)能够最好地近似每一个\(s\)的\(v_\pi(s)\)。具体而言,目标函数为
其中\(S \in \mathcal{S}\)是随机变量。由于\(S\)是一个随机变量,那么它的概率分布是什么?这是本书第一次将状态描述成随机变量,并需要刻画其概率分布,这也是使用值函数时要解决的重要问题。
定义\(S\)的概率分布有以下几种方式。
-
第一种方法是采用均匀分布(uniform distribution)。即将每个状态的概率设为\(1/n\),将所有状态视为同等重要。此时,式\((8.3)\)中的目标函数变为
\[J(w)=\frac{1}{n}\sum_{s\in\mathcal{S}}(v_\pi(s)-\hat{v}(s,w))^2,\tag{8.4}\]这是所有状态的估计误差的平均值。这种方法的问题在于没有考虑给定策略下马尔可夫过程的真实动态。例如,某些状态可能很少被访问到,此时将所有状态视为同等重要可能并不合理。
-
第二种方法是利用稳态分布(stationary distribution),这也是本章的重点。稳态分布描述了马尔可夫决策过程的长期行为(long-run behavior);具体而言,当智能体执行一个给定策略足够长时间后,智能体位于任意一个状态的概率都可以由这个稳态分布表示。感兴趣的读者可参阅Box\(8.1\)获取细节。
具体来说,设\(\{d_\pi(s)\}_{s\in\mathcal{S}}\)表示策略\(\pi\)下马尔可夫过程的稳态分布。即经过相当长的时间后,智能体在状态\(s\)的概率为\(d_\pi(s)\)。根据定义,满足\(\sum_{s\in\mathcal{S}}d_\pi(s)=1\)。因此,\((8.3)\)中的目标函数可改写为
\[J(w)=\sum_{s\in\mathcal{S}}d_\pi(s)(v_\pi(s)-\hat{v}(s,w))^2,\tag{8.5}\]这是对所有状态的估计误差的加权平均值。那些有更高访问概率的状态被赋予更大的权重。
Note
long-run behavior就是从某一个状态出发,然后我按照策略采取行动,然后不断地去和环境进行交互,然后一直采取这个策略,采取非常多次之后,我就达到了一种平稳的状态,在那个平稳的状态下就得到在每一个状态智能体出现它的概率是多少。
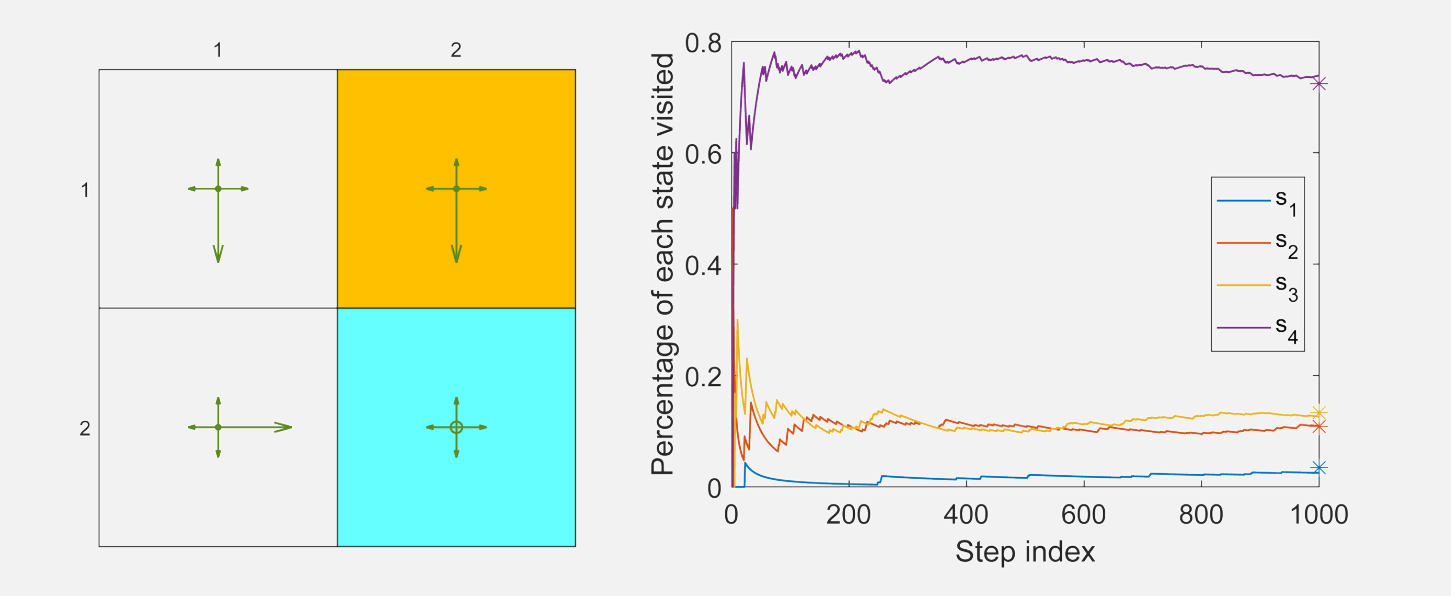
图\(8.5\):\(\varepsilon=0.5\)的\(\varepsilon\)-贪心策略长期行为。右图中星号表示向量\(d^\pi\)各分量的理论值。
值得注意的是,求解\(d_\pi(s)\)的具体值并非易事,因为它需要知道状态转移概率矩阵\(P^\pi\)(感兴趣读者可以阅读Box\(8.1\))。幸运的是,我们不需要计算\(d_\pi(s)\)的具体值就可最小化该目标函数。具体细节留给下一节讨论。
最后,在引入式\((8.4)\)和\((8.5)\)时,我们假设状态数量是有限的和离散的。当状态空间连续时,我们需要通过积分求和。
8.2.2 优化算法¶
为了最小化式\((8.3)\)中的目标函数\(J(w)\),我们可采用梯度下降算法:
其中的梯度是
将上面梯度表达式代入梯度下降算法可得
其中\(\alpha_k\)前面的系数\(2\)可以不失一般性地合并到\(\alpha_k\)中。
式\((8.11)\)的算法无法直接使用,因为它需要计算真实期望值,而真实期望值在实际中难以获得。此时,我们可以根据随机梯度下降法的思想,用随机梯度替代真实梯度。那么\((8.11)\)式可改写为
其中\(s_t\)是\(S\)在时刻\(t\)的采样值。
值得注意的是,\((8.12)\)式不可直接实现,因为它需要真实的状态值\(v_\pi\),这是未知的值且需要通过估计获得。此时我们可以用近似值替代\(v_\pi(s_t)\),具体来说有以下两种方法。
-
蒙特卡洛方法:假设我们有一个回合\((s_0,r_1,s_1,r_2,\ldots)\)。令\(g_t\)表示从状态\(s_t\)开始的折扣回报,那么\(g_t\)可以作为\(v_\pi(s_t)\)的估计值。此时式\((8.12)\)中的算法可改写为
\[w_{t+1}=w_t+\alpha_t\left(g_t-\hat{v}(s_t,w_t)\right)\nabla_w\hat{v}(s_t,w_t).\]这是基于值函数的蒙特卡洛学习算法。
-
时序差分法:根据时序差分的思想,我们可以用TD误差\(r_{t+1}+\gamma\hat{v}(s_{t+1},w_t)-\hat{v}(s_t,w_t)\)来代替真实误差\(v_\pi(s_t)-\hat{v}(s_t,w_t)\)。此时\((8.12)\)式中的算法变为
\[w_{t+1}=w_t+\alpha_t\left[r_{t+1}+\gamma\hat{v}(s_{t+1},w_t)-\hat{v}(s_t,w_t)\right]\nabla_w\hat{v}(s_t,w_t).\tag{8.13}\]这是基于值函数的TD算法。详细流程见算法\(8.1\)。

算法\(8.1\): 基于值函数的TD算法(用于状态值估计)。
理解式\((8.13)\)中的TD算法对于理解本章的其他算法至关重要。值得注意的是,\((8.13)\)是用于估计状态值的。在\(8.3.1\)和\(8.3.2\)节中,我们将把它扩展到行动值估计。
8.2.3 选择值函数¶
为应用\((8.13)\)中的TD算法,我们需要选择合适的值函数\(\hat{v}(s, w)\)。
具体有两种实现方式,目前最常用的是采用人工神经网络作为,其输入为状态\(s\),输出为\(\hat{v}(s, w)\),网络参数为\(w\)。下面重点介绍历史上早期使用较广泛的线性函数,其优势是具有较强的理论可解释性,其劣势是具有较弱的近似能力,并且实际中往往难以选取合适的特征向量(feature vector)。不过作为最简单的情况,它对于我们理解基于值函数的TD方法非常重要。
一个最线性函数通常具有以下形式:
其中\(\phi(s) \in \mathbb{R}^m\)表示状态\(s\)的特征向量。\(\phi(s)\)与\(w\)的维度均为\(m\),\(m\)通常远小于状态的个数。例如,如果函数对应的是一阶直线或者二阶曲线(参见(8.1)和(8.2)),那么对应的\(m\)等于2或者3.值得注意的是,这里的线性函数指的是函数对\(w\)呈线性,而并非对\(s\)呈线性,例如\((8.2)\)中的函数不是\(w\)的线性函数,而是\(s\)的二次非线性函数。
线性函数的梯度非常简单:
将其代入式\((8.13)\)可得
这是采用基于线性值函数的TD算法,简称为TD-Linear。
线性情况比非线性情况有更强的理论可解释性。然而其近似能力有限,并且选择合适的特征向量也并非易事。相比之下,人工神经网络作为通用非线性函数近似器,能够近似更加复杂的函数,而且不需要选择特征向量。使用起来也更为方便。
尽管如此,学习线性情况仍具重要意义。第一,基于表格的TD方法可以被视为一种特殊的基于线性值函数的TD算法。这个结论非常重要,一方面其统一了表格和值函数两种方法,另一方面也说明了线性值函数方法的强大。关于这个结论的更多细节可参见Box\(8.2\)。第二,理解线性情况可以帮助读者更好地掌握值函数的方法的思想。第三,对于简单的网格世界任务,线性情形已足以解决问题。
8.2.4 例子¶
接下来我们通过一些例子来展示如何使用\((8.14)\)中的TD-Linear算法来估计给定策略的状态值,同时,我们也将展示如何选择特征向量。
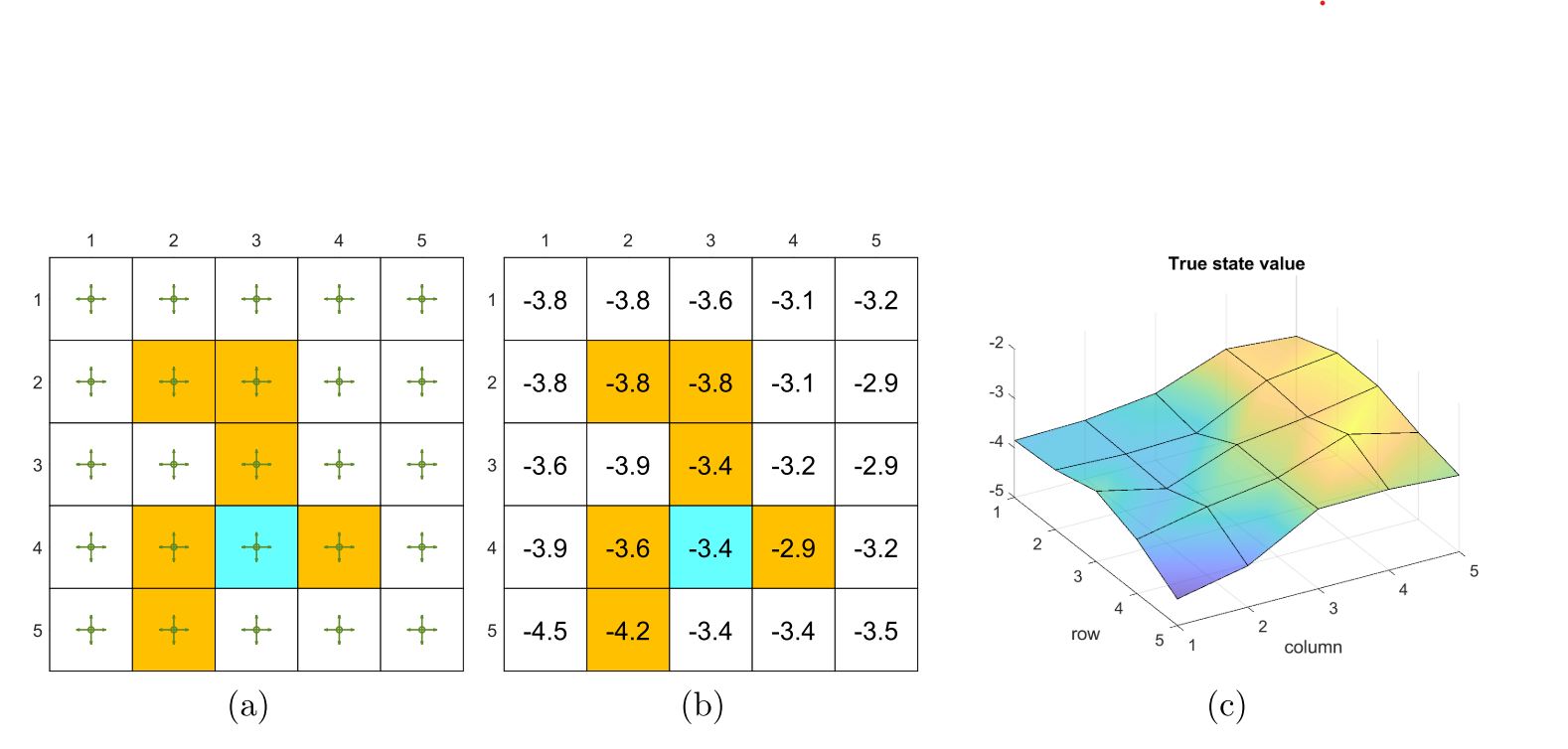
图\(8.6\):\((a)\)待评估策略。\((b)\)真实状态值以表格形式呈现。\((c)\)真实状态值以三维曲面形式呈现。
图\(8.6\)给出了一个网格世界例子。图\(8.6(a)\)展示的是一个给定的策略,它在每个状态下采取任意动作的概率都是\(0.2\)。我们的任务是估计此策略下的状态值。首先通过求解贝尔曼方程的方式可以得到真实状态值,如图\(8.6(b)\)所示,其三维曲面可视化结果展示在图\(8.6(c)\)中。
Note
总共有25个状态值,如果用表格的方式,那么需要存储25个状态值。
接下来我们证明,可以用少于\(25\)个参数来近似状态值。仿真设置如下:通过给定策略生成\(500\)个回合,每个回合包含\(500\)步,并从一个按均匀分布随机选择的状态-动作开始。此外,在每次仿真中,参数向量\(w\)被随机初始化,其中每个元素均从均值为\(0\)且标准差为\(1\)的正态分布中采样得到。我们设定\(r_{\text{forbidden}} = r_{\text{boundary}} = -1\),\(r_{\text{target}} =1\),以及\(\gamma =0.9\)。
为了应用TD-Linear算法,首先需要选择特征向量\(\phi(s)\)。有多种方法来选择特征向量。
-
第一种特征向量基于多项式构建。在网格世界示例中,一个状态\(s\)对应一个二维坐标位置,其中\(x\)和\(y\)分别表示\(s\)的列索引与行索引。为避免数值问题,我们将\(x\)和\(y\)归一化至区间\([-1, +1]\)内。为方便起见,归一化后的值仍用\(x\)和\(y\)表示。那么最简单的特征向量可表示为
\[\phi(s)=\begin{bmatrix}x\\y\end{bmatrix}\in\mathbb{R}^2.\]此时对应的线性函数是
\[\hat{v}(s,w)=\phi^T(s)w=[x,y]\begin{bmatrix}w_1\\w_2\end{bmatrix}=w_1x+w_2y.\]当给定\(w\)时而\(x,y\)是自变量,那么\(\hat{v}(s, w) = w_1x + w_2y\)表示一个通过原点的二维平面。由于状态值近似对应的平面可能不经过原点,我们需要引入一个偏置项以更好地近似状态值。为此,我们考虑以下三维特征向量:
\[\phi(s)=\begin{bmatrix}1\\x\\y\end{bmatrix}\in\mathbb{R}^3.\tag{8.15}\]在此情况下,值函数为
\[\hat{v}(s,w)=\phi^T(s)w=[1,x,y]\begin{bmatrix}w_1\\w_2\\w_3\end{bmatrix}=w_1+w_2x+w_3y.\]当给定\(w\)时而\(x,y\)是自变量,\(\hat{v}(s, w)\)对应一个可能不经过原点的平面。值得注意的是\(\varphi(s)\)也可以定义为\(\varphi(s) = [x, y,1]^T\),其中元素的顺序没有关系。
基于式\((8.15)\)中特征向量,如果我们使用TD-Linear苏娜发,最后得到的值函数如图\(8.7(a)\)所示。尽管估计误差会随着更多回合而逐渐收敛,但由于二维平面的近似能力有限,该误差仍然无法降至零。
为了增强近似能力,可通过增加特征向量的维度实现。例如考虑使用以下六维特征向量:
\[\phi(s)=[1,x,y,x^2,y^2,xy]^T\in\mathbb{R}^6.\tag{8.16}\]此时,线性值函数的表达式是\(\hat{v}(s, w) = \varphi^T(s)w = w_1 + w_2x + w_3y + w_4x^2 + w_5y^2 + w_6xy\),对应一个三维曲面。当然我们可以进一步增加特征向量的维度:
\[\phi(s)=[1,x,y,x^2,y^2,xy,x^3,y^3,x^2y,xy^2]^T\in\mathbb{R}^{10}.\tag{8.17}\]使用式\((8.16)\)和\((8.17)\)中特征向量时,TD-Linear的估计结果如图\(8.7(b)-(c)\)所示。可以看出,特征向量维度越高,状态值的近似就越精确。然而,在这三种情况下,估计误差均无法收敛至零,这是因为这些线性函数的近似能力仍然有限。
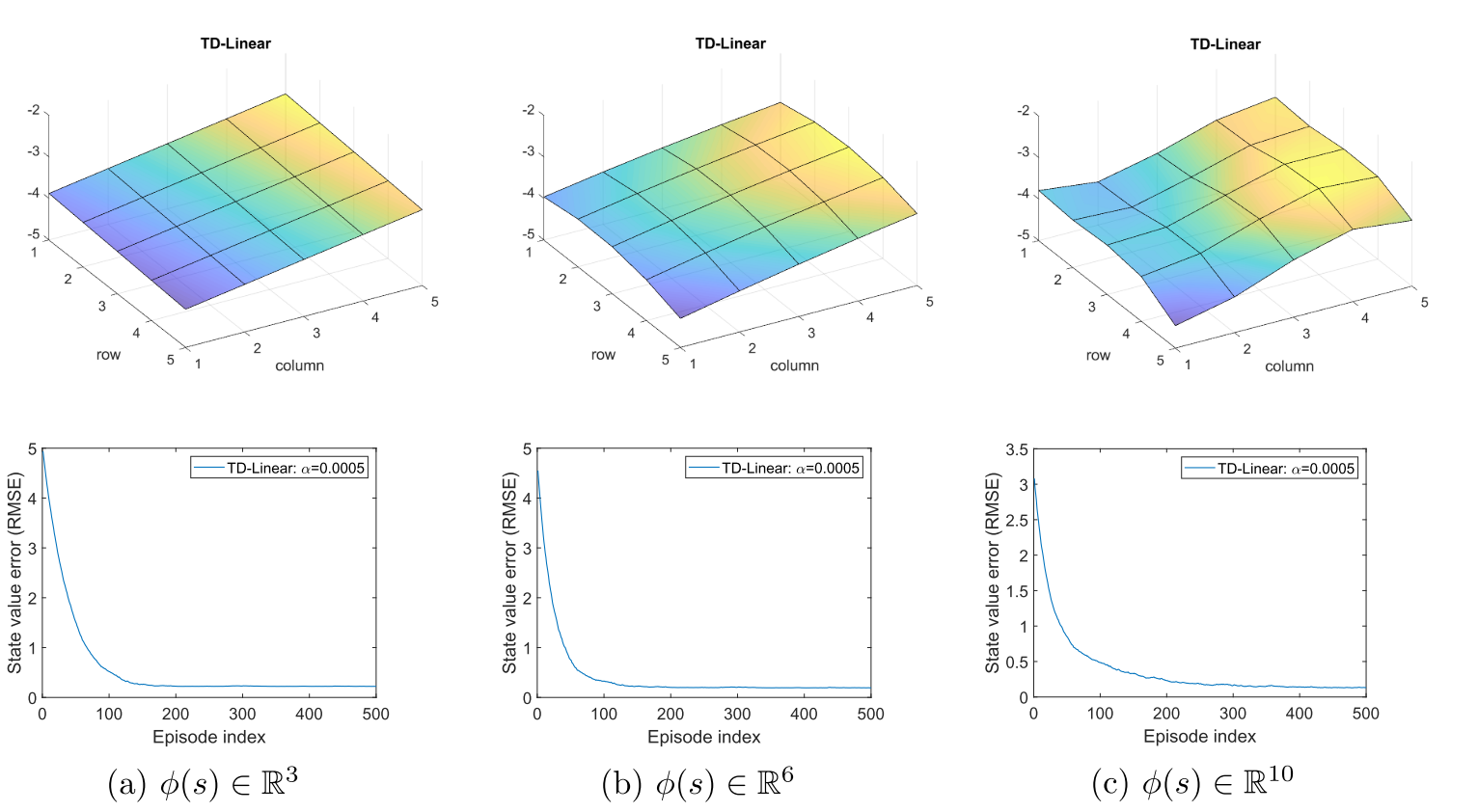
图\(8.7\):采用多项式特征\((8.15)\),\((8.16)\)和\((8.17)\)得到的TD-Linear估计结果。
-
除了基于多项式的特征向量,还存在多种其他类型的特征向量,例如傅里叶基(Fourier basis)和片编码(Tile coding)[3,第9章]。首先,需使变量\(x\)与\(y\)归一化至区间[0,1]。基于傅里叶基的特征向量是:
\[\left.\phi(s)=\left[\begin{array}{c}\vdots\\\cos\left(\pi(c_1x+c_2y)\right)\\\vdots\end{array}\right.\right]\in\mathbb{R}^{(q+1)^2},\tag{8.18}\]其中\(\pi\)表示圆周率而不是策略。此处\(c_1\),\(c_2\)可以从集合\(\{0,1, ..., q\}\)中取值,其中\(q\)为用户指定的整数。因此,二元组\((c_1, c_2)\)共有\((q +1)^2\)种可能的取值组合,故特征\(\phi(s)\)的维度为\((q +1)^2\)。例如当\(q=1\)时,特征向量可表示为
\[\left.\phi(s)=\left[\begin{array}{c}\cos\left(\pi(0x+0y)\right)\\\cos\left(\pi(0x+1y)\right)\\\cos\left(\pi(1x+0y)\right)\\\cos\left(\pi(1x+1y)\right)\end{array}\right.\right]=\begin{bmatrix}1\\\cos(\pi y)\\\cos(\pi x)\\\cos(\pi(x+y))\end{bmatrix}\in\mathbb{R}^4.\]采用\(q =1,2,3\),那么使用TD-Linear算法获得的结果如图\(8.8\)所示。在这三种情况中,特征向量的维度分别为\(4,9,16\)。可以看出,特征向量维度越高,状态值的近似精度越高。
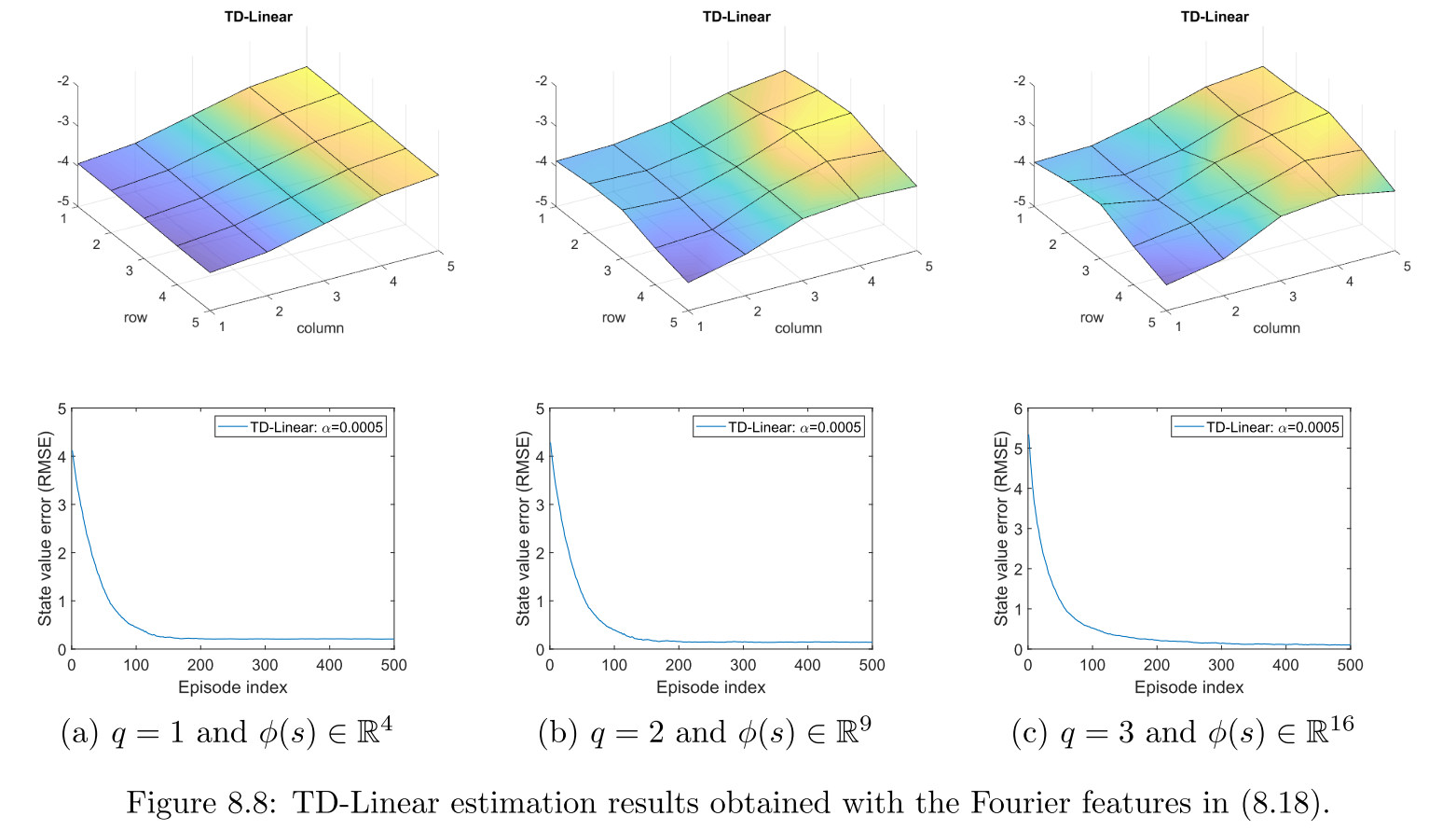
图\(8.8\):采用式\((8.18)\)中傅里叶特征向量使用TD-Linear算法估计的结果。
8.2.5 理论分析¶
前面几个小节介绍了基于值函数的TD算法。我们介绍的思路始于\((8.3)\)中的目标函数。为了优化这个目标函数,我们引入了\((8.12)\)中的随机梯度算法。后来,该算法中未知的真实状态值被一个近似值替代,从而产生了\((8.13)\)中的TD算法。
这个介绍思路非常直观易懂,不过它在数学上并不严谨。例如,\((8.13)\)中的算法实际上并不是在优化\((8.3)\)中的目标函数。不过对于大部分读者来说,了解这个思路脉络已经足够了。
接下来,我们对式\((8.13)\)中的TD算法进行严格的理论分析,以揭示该算法为何能够有效工作以及其究竟解决了什么数学问题。由于非线性函数难以分析,因此这部分仅讨论线性值函数的情况。这部分内容涉及大量的数学内容,建议读者根据自己的兴趣选读,直接跳过本小节不会影响后续学习。
收敛性分析¶
为研究式 (8.13)的收敛性,我们首先考察以下算法:
其中期望值是关于随机变量\(s_t\),\(s_{t+1}\).\(r_{t+1}\)计算的。式\((8.19)\)中的算法是确定性的,因为所有随机变量在计算期望后都消失了。
我们为何考虑\((8.19)\)这一确定性算法?首先,该确定性算法的收敛性更为简便(尽管其分析也并非一蹴而就);更重要的是,该确定性算法的收敛性可推导出算法\((8.13)\)的收敛性。这是因为\((8.13)\)可视为\((8.19)\)的随机梯度下降(SGD)版本。因此,我们仅需研究该确定性算法的收敛性。
虽然式\((8.19)\)的表达式乍看较为复杂,但实际上可以大大简化。假设\(s_t\)服从平稳分布\(d_\pi\)。定义
其中\(\Phi\)为包含所有特征向量的矩阵(每一行对应一个状态的特征向量),\(D\)是以平稳分布为对角元素的对角矩阵。基于这两个矩阵,我们可以将\((8.19)\)大大简化
Info
引理8.1. 式\((8.19)\)中的期望可改写为
在这里
此处,\(P_\pi\)和 \(r_\pi\)是贝尔曼方程\(v_\pi = r_\pi + \gamma P_\pi v_\pi\)中的两项,\(I\)为相应维度的单位矩阵。
该引理的证明过程见Box 8.3。
根据引理\(8.1\)中的表达式,确定性算法\((8.19)\)可改写为
这是一个确定性迭代算法,其收敛性分析如下所示。
第一,我们先回答一个问题:假设当\(t\rightarrow \infty\)时,\(w_t\)收敛至常数值\(w^∗\),那么\(w^*\)是多少?如果已经收敛,那么\((8.22)\)中的\(w_t,w_{t+1}\)就变为\(w^*\),所以有\(w^∗ = w^∗ + \alpha_\infty(b − Aw^*)\),进而可得\(b − Aw^* =0\),因此
关于该收敛值的几点说明如下。
-
矩阵\(A\)是否可逆?答案是肯定的。事实上,\(A\)不仅可逆,还是正定矩阵(非对称的)。即对于任意合适维度的非零向量 \(x\),均有\(x^T Ax >0\)。证明过程见Box 8.4。
-
\(w^* = A^{-1}b\)的含义?它实际上是最小化投影贝尔曼误差(projected Bellman error)的最优解。详细内容将在第8.2.5节中阐述。
-
我们已经在Box8.2中介绍过:如果选择特殊的特征向量,基于值函数的TD-Linear算法就退化为基于表格的TD算法。下面我们把这个特殊的特征向量带入\(w^*\),看能够得到什么有意思的结论。具体来说,选择特征向量为\(\phi(s) = [0, \ldots,1, \ldots,0]^T\)(其中与状态\(s\)对应的元素为\(1\),其他都为\(0\)),将其带入\((8.21)\)中可得
\[w^*=A^{-1}b=v_\pi.\tag{8.23}\]
上式表明,该TD-Linear算法学习的参数就是真实的状态值。因为基于表格的TD算法就是在估计状态值,这一结论与基于表格TD算法是TD-Linear算法的一个特例。式\((8.23)\)的证明如下:首先不难看出\(\Phi = I\),因此\(A = \Phi^\text{T}D(I - \gamma P^\pi)\Phi = D(I - \gamma P^\pi)\)且\(b = \Phi^\text{T}Dr^\pi = Dr^\pi\)。故而有\(w^* = A^{-1}b = (I - \gamma P^\pi)^{-1}D^{-1}Dr^\pi = (I - \gamma P^\pi)^{-1}r^\pi = v^\pi\)。
第二,我们证明当\(t \to \infty\)时,\((8.22)\)式中的\(w_t\)收敛于\(w^* = A^{-1}b\)。由于\((8.22)\)式是一个简单的确定性迭代算法,因此可通过多种方法证明。下面给出两种证明方式。
-
证明方法1: 定义收敛误差为\(\delta_t = w_t - w^*\)。只需证明\(\delta_t\)收敛于零即可。为此,将\(w_t = \delta_t + w^*\)代入\((8.22)\)可得
\[\delta_{t+1}=\delta_t-\alpha_tA\delta_t=(I-\alpha_tA)\delta_t.\]由此可得
\[\delta_{t+1}=(I-\alpha_tA)\cdots(I-\alpha_0A)\delta_0.\]考虑一个简单情况:对所有时刻 \(t\)有\(\alpha_t = \alpha\)的,对上面等式两边求范数可得
\[\|\delta_{t+1}\|_2\leq\|I-\alpha A\|_2^{t+1}\|\delta_0\|_2.\]当\(\alpha >0\)充分小时,有\(\|I - \alpha A\|_2 <1\),因此当\(t \to \infty\)时\(\delta_t \to0\)。不等式\(\|I - \alpha A\|_2 <1\)成立的原因是\(A\)正定,故对任意\(x\)均有\(x^T(I - \alpha A)x <1\)。
-
证明方法2: 考虑函数\(g(w) = b - Aw\)。由于\(w^*\)是方程\(g(w) =0\)的根,该问题本质上是一个求解方程的问题。而式\((8.22)\)中的算法实际上是第六章介绍的罗宾斯-门罗(RM)算法。虽然原始RM算法是为随机过程设计的,但它同样适用于确定性情况。RM算法的收敛性可以揭示\(w_{t+1} = w_t + \alpha_t(b - Aw_t)\)的收敛性:即当\(\sum_t \alpha_t = \infty\)并且\(\sum_t \alpha_t^2 < \infty\)时,\(w_t\)将收敛至\(w^*\)。
证明1和证明2给出了算法\((8.22)\)收敛的两种条件。证明1说明了,当\(\alpha_t\)是一个足够小的常数时,算法收敛。证明2说明了,当\(\alpha_t\)满足\(\sum_t \alpha_t=\infty\)和\(\sum_t \alpha_t^2<\infty\)时,\(w_t\)收敛于\(w^*\)。这两个条件在第六章介绍随机近似算法时也经常见到。
至此,我们证明了\((8.22)\)的收敛性,由于\((8.13)\)也可以被视为\((8.19)\)的随机梯度下降版本,因此其收敛性也可以得到。
TD学习最小化投影贝尔曼误差¶
虽然我们已经证明TD-Linear算法收敛于\(w^* = A^{-1}b\),但接下来我们将证明TD-Linear算法实际上是在最小化投影贝尔曼误差。为此,我们首先梳理三个目标函数。
-
第一个目标函数是
\[J_E(w)=\mathbb{E}[(v_\pi(S)-\hat{v}(S,w))^2],\]本章最开始就是使用这个目标函数来介绍值函数方法思路的。该目标函数也可以等价写成一个矩阵-向量形式:
\[J_E(w)=\|\hat{v}(w)-v_\pi\|_D^2,\]其中 \(v_\pi\)为真实状态值向量,\(\hat{v}(w)\)为估计的值向量,这两个向量的每一个元素都对应一个状态。此处 \(\|\cdot\|_D\)为加权范数:\(\|x\|_D^2 = x^\top D x = \|D^{1/2}x\|_2^2\),其中 \(D\)由式 (8.20)给出。
这是我们目前能设想的最简单目标函数之一。然而,它依赖于未知的真实状态值。所以直接优化它是无法得到可行的算法的。因此我们必须考虑其他目标函数,例如贝尔曼误差和投影贝尔曼误差[50–54]。
-
第二个目标函数是贝尔曼误差(Bellman error)。具体来说,由于\(v_\pi\)满足贝尔曼方程\(v_\pi = r_\pi + \gamma P_\pi v_\pi\),因此估计值\(\hat{v}(w)\)也应尽可能满足此方程。贝尔曼误差的定义为
\[J_{BE}(w)=\|\hat{v}(w)-(r_\pi+\gamma P_\pi\hat{v}(w))\|_D^2\doteq\|\hat{v}(w)-T_\pi(\hat{v}(w))\|_D^2.\tag{8.30}\]此处的\(T_\pi(\cdot)\)为贝尔曼算子。对于任意向量 \(\mathbf{x} \in \mathbb{R}^n\)有
\[T_\pi(x)\doteq r_\pi+\gamma P_\pi x.\]最小化贝尔曼误差是一个标准的最小二乘问题。具体细节不再赘述。
-
第三个目标函数是投影贝尔曼误差(projected Bellman error),其定义为
\[J_{PBE}(w)=\|\hat{v}(w)-MT_\pi(\hat{v}(w))\|_D^2,\]其中\(M \in \mathbb{R}^{n \times n}\)为正交投影矩阵,它在几何上,可以将任意向量投影至函数能够近似的值空间上。矩阵\(M\)的表达式将在\((8.31)\)给出。
事实上,\((8.13)\)中的TD算法旨在最小化投影贝尔曼误差\(J_{PBE}\),而不是\(J_E\)或\(J_{BE}\)。而且\(J_{PBE}\)一定可以被最小化到0。严格的数学证明见Box8.5,直观原因如下所述。在线性情况下,\(\hat{v}(w) = \Phi w\),其中\(\Phi\)由\((8.20)\)式定义。\(\Phi\)的列空间(range space)是该线性函数所有可能取值构成的集合。此时,
是一个可以将任意向量投影到\(\Phi\)的列空间的投影矩阵。由于\(\hat{v}(w)\)位于 \(\Phi\)的列空间内,因此我们总能找到一个使\(J_{PBE}(w)\)最小化至0的\(w\)值。可以证明,最小化\(J_{PBE}(w)\)的解就是\(w^* = A^{-1}b\)。即
证明在Box 8.5中给出
最小二乘时序差分算法¶
接下来我们介绍一种称为最小二乘时序差分(Least-squares TD, LSTD)的算法[57]。与TD-Linear算法类似,LSTD的目标是最小化投影贝尔曼误差。不过它相较于TD-Linear算法具有若干优势。详情如下所述
回顾最小化投影贝尔曼误差的最优参数为\(w^* = A^{-1}b\),其中\(A = \Phi^TD(I - \gamma P^\pi)\Phi\)且\(b = \Phi^TDr^\pi\)。由式\((8.27)\)可知,\(A\)和\(b\)亦可写为
上式中的期望是针对于随机变量是 \(s_t\)、\(s_{t+1}\)、\(r_{t+1}\)而言的。
LSTD算法的思路很简单:既然我们已经知道最优解的表达式为\(w^*=A^{-1}b\),那么可以使用随机样本直接获得\(A\)和\(b\)的估计量,假设获得的估计值为\(\hat{A}\)与\(\hat{b}\),则可以直接得到最优参数的估计为\(w^* \approx \hat{A}^{-1}\hat{b}\)。这个思路的核心是充分利用我们对最优解的理论知识。一般来说,对问题理解越深入,设计的算法就越好。
具体而言,假设\((s_0, r_1, s_1, \ldots, s_t, r_{t+1}, s_{t+1}, \ldots)\)是根据给定策略\(\pi\)所获得的轨迹。设\(\hat{A}_t\)和 \(\hat{b}_t\)分别为时刻\(t\)时\(A\)和\(b\)的估计值,它们可以通过计算样本的平均值得到:
因此在\(t\)时刻最优参数的估计值为
读者可能会疑惑\((8.35)\)式右侧是否遗漏了\(1/t\)的系数。实际上,如果\(\hat{A}_t\)和\(\hat{b}_t\)都除以\(t\),由于\(w_t\)会对\(\hat{A}_t\)求逆,因此最后得到的结果和不除以\(t\)是一样的。此外\(\hat{A}_t\)是不可逆的,特别在\(t\)较小样本较少的时候。为此,需要向\(\hat{A}_t\)添加一个小的常数矩阵\(\sigma I\)再来求逆(其中\(I\)为单位矩阵,\(\sigma\)为微小正数)。
LSTD算法的优势在于它使用经验样本更为高效,并且比TD-Linear收敛速度更快。这是因为该算法是专门基于最优解表达式的知识专门设计的。
但LSTD算法的也存在一些缺点如下。第一,它只能估计状态值;相比之下,前面介绍的TD算法可扩展至行动值估计(下一章我们将要介绍)。第二,TD算法允许使用非线性函数,而LSTD只适用于线性函数——这是因为该算法是基于线性情况下最优解\(w^*\)的表达式专门设计的。第三,LSTD的计算成本高于TD算法:LSTD在每次更新步骤中需处理\(m \times m\)矩阵,并且需要计算\(\hat{A}_t\)的逆矩阵,其计算复杂度为\(O(m^3)\)。解决该问题的方法是直接更新\(\hat{A}_t\)的逆矩阵而非\(\hat{A}_t\)本身,具体而言,\(\hat{A}_{t+1}\)可通过如下递归方式计算:
上述表达式将 \(\hat{A}_{t+1}\)分解为两个矩阵之和,其根据矩阵和的逆的性质[58],可以计算得到
这样我们可以直接存储并更新\(\hat{A}^{-1}_t\),以避免计算矩阵的逆。这种迭代算法不需要设置步长,但需要给定\(\hat{A}^{-1}_0\)的初始值。一般该初始值可选为\(\hat{A}^{-1}_0 = \sigma I\),其中\(\sigma\)为一个较小的正数。关于迭代最小二乘法的详细教程可参阅文献[59]。