8.4-深度Q-learning
我们可以将深度神经网络整合到Q-learning中,从而得到一种称为深度Q-learning(deep Q-learning)或深度Q网络(deep Q-network, DQN)的方法[22,60,61]。深度Q-learning是最早且最成功的深度强化学习算法之一。值得注意的是,对于简单任务,神经网络并不需要很深。(例如我们的网格世界示例),仅含一两个隐藏层的浅层网络可能已足够。深度Q-learning可视为式\((8.36)\)算法的扩展,但其数学表述与实现技术存在显著差异,详见下文。
8.4.1 算法描述¶
从数学角度而言,深度Q-learning旨在最小化以下目标函数:
其中 \((S, A, R, S')\)为随机变量,分别表示状态、动作、即时奖励和下一状态。
如何理解这个目标函数呢?实际上,它对应了贝尔曼最优性误差,当\(\hat{q}(S, A,w)\)能准确近似最优行动值时,\(R + \gamma \max_{a\in \mathcal{A}(S')} \hat{q}(S', a, w) - \hat{q}(S, A,w)\)在期望意义上应该等于0。这可以由下面的贝尔曼最优方程看出:
这正是贝尔曼最优方程(证明过程见Box7.5)。
如何最小化式\((8.37)\)中的目标函数呢?可采用梯度下降算法。为此,需计算\(J\)关于\(w\)的梯度。值得注意的是,参数\(w\)不仅出现在\(\hat{q}(S, A, w)\)中,还隐含于\(y \doteq R + \gamma \max_{a \in \mathcal{A}(S')} \hat{q}(S', a, w)\)的表达式内,其梯度的计算并非易事。因此,可以假设\(y\)中\(w\)的值在短时间内是固定不变的,这样就可以比较容易地计算梯度。具体来说,我们引入两个网络:一个主网络(main network)用于表示\(\hat{q}(s, a, w)\),另一个目标网络(target network)表示\(\hat{q}(s, a, w_T)\)。此时目标函数变为
Question
为什么可以假设\(y\)中的\(w\)值在短时间内保持固定
当\(w_T\)固定不变时,容易计算出\(J\)的梯度为
上式忽略了一些不重要的常数系数。
为利用式\((8.38)\)中的梯度最小化目标函数,需注意以下技术要点。
-
第一种技术是使用两个网络——主网络和目标网络,具体实现细节如下:令\(w\)和\(w_T\)分别表示主网络与目标网络的参数,它们的初始值相同。
在每次迭代中,我们从回放缓冲区(replay replay)中抽取一个小批量样本 \(\{(s, a, r, s')\}\)。主网络的输入为状态\(s\)和行动\(a\),其输出 \(y = \hat{q}(s, a, w)\)表示估计的q值,输出的目标值为 \(y_T \doteq r + \gamma \max_{a \in \mathcal{A}(s')} \hat{q}(s', a, w_T)\)。主网络的更新是为了最小化样本\(\{(s, a, y_T)\}\)上的TD误差(也称为损失函数)\(\mathbb{E}[(y - y_T)^2]\)。
更新主网络中的参数并不是显式地使用式\((8.38)\)中的梯度。相反,它需要小批量样本并基于现有的神经网络训练工具来更新参数。这是深度与非深度强化学习算法之间的显著区别。
虽然主网络在每次迭代中都会更新。但是目标网络却是每隔固定次数的迭代后更新为与主网络相同的参数,以满足计算式\((8.38)\)梯度时\(w_T\)是固定不变的假设。
-
第二种技术是经验回放(experience replay)[22,60,62]。当我们收集到若干经验样本后,我们并不会按照它们被收集的顺序直接使用这些样本,而是将其存储在一个被称为回放缓冲区的集合中。例如,设\((s, a, r, s')\)为一个经验样本,\(\mathcal{B} := \{(s, a, r, s')\}\)为回放缓冲区。每次更新主网络时,从回放缓冲区中均抽取小批量经验样本,这个过程被称为经验回放。抽取经验样本时应该服从均匀分布。
为什么深度Q-learning中需要经验回放?为什么经验回放应该遵循均匀分布?答案在于式\((8.37)\)中的目标函数。具体而言,为了定义该目标函数,我们必须指定状态\(S\)、行动\(A\)、奖励\(R\)及\(S'\)的概率分布。当\((S,A)\)给定时,\(R\)与\(S'\)的分布由系统模型决定。因此,我们只需要指定\((S,A)\)的分布。如果我们没有对采样过程的先验知识,那么最简单的方法是假设它是均匀分布的。然而,实际中对\((S,A)\)采样可能并非是均匀分布的,为了满足均匀分布假设,必须打破序列中样本间的相关性。为此可以使用经验回放技术,按照均匀分布从回放缓冲区中抽取样本。这是经验回放的必要性和为什么服从均匀分布的理论原因。最后随机采样的一个优势在于每个经验样本可多次重复使用,从而提高数据利用效率。这一特性在数据量有限时尤为重要。
Note
假设先验这里用到了一些贝叶斯计算的思想,后面可能会针对该问题开一个专题。
Note
\(R\sim p(R|S,A),S^{\prime}\sim p(S^{\prime}|S,A)\)。其他的分布比如高斯分布行不行?我想给一些\((S,A)\)更大的权重,那么在采样的时候当然也要更多次的去运用到他们,它的一个问题就是你要有先验知识,要知道谁是重要的,谁是不重要的。如果没有这个先验知识,就要一视同仁,所有的\((S,A)\)的概率都应该是相同的,这时候就是均匀分布
深度Q学习的实现流程总结于算法8.3中。该实现采用Off-policy方法,必要时也可调整为On-policy形式。
8.4.2 例子¶
图\(8.11\)给出了一个演示算法\(8.4\)的例子。其任务是得到每个状态-行动的最优行动值,从而得到最优策略。
行为策略如图\(8.11(a)\)所示,该行为策略具有探索性,表现为它在任何状态下采取任意动作的概率都是相同的。由该行为策略生成的一个有\(1000\)步的回合如图\(8.11(b)\)所示。尽管步数有限,但由于行为策略强大的探索能力,该回合几乎覆盖了所有状态-动作对。回放缓冲区存储了\(1,000\)个经验样本,每次训练的批量大小都是\(100\),意味着每次采样时需从缓冲区均匀抽取\(100\)个样本。
主网络与目标网络具有相同结构,即一个包含100个神经元的单隐藏层的神经网络(层数和神经元数量可以自己调整)。该网络具有三个输入和一个输出,前两个输入为状态对应的归一化后的行和列的索引,第三个输入为归一化后的行动索引。此处的“归一化”指将数值转换至区间\([0,1]\)。该网络输出为估计的最优值。
我们将输入设计为状态的行列坐标而非状态索引,是因为我们已知状态对应网格中的二维位置。在设计神经网络时使用的关于状态的先验信息越多,学习的效果就越好。当然,网络也可以有其他设计方式。例如,它可以有2个输入和5个输出,其中两个输入为归一化的行与列,输出则是输入状态对应的五个行动的值估计[22]。
基于上述网络,学习的过程如图8.11(d)~(e)所示,其中损失函数对应每个小批量平均TD误差的平方,可以看到损失函数逐渐收敛到0,这意味着网络可以很好地拟合训练样本。另外,值估计误差同样收敛到0,这意味着最优动作值估计已达到足够精度。进而得到的贪婪策略即为最优策略。
这个例子很好展示了深度Q-learning的高效性。具体而言,仅需1,000步的回合就足以学习到最优策略;相比之下,如图7.4所示,基于表格的Q-learning需要100,000步的回合才能收敛。其高效性原因之一在于值函数方法相比于表格法具有更强的泛化能力,此外经验样本可被重复利用,具有较高的数据使用效率。
接下来,我们通过设计一个经验样本较少的场景,对深度Q-learning算法进行检验。图8.12展示了一个仅包含100步的回合。虽然损失函数收敛至零(网络得以很好地训练),但是值估计误差仍无法收敛到零(图8.12(e))。这表明网络虽然能够正确拟合给定的经验样本,但由于经验样本数量不足,难以准确估计最优值。
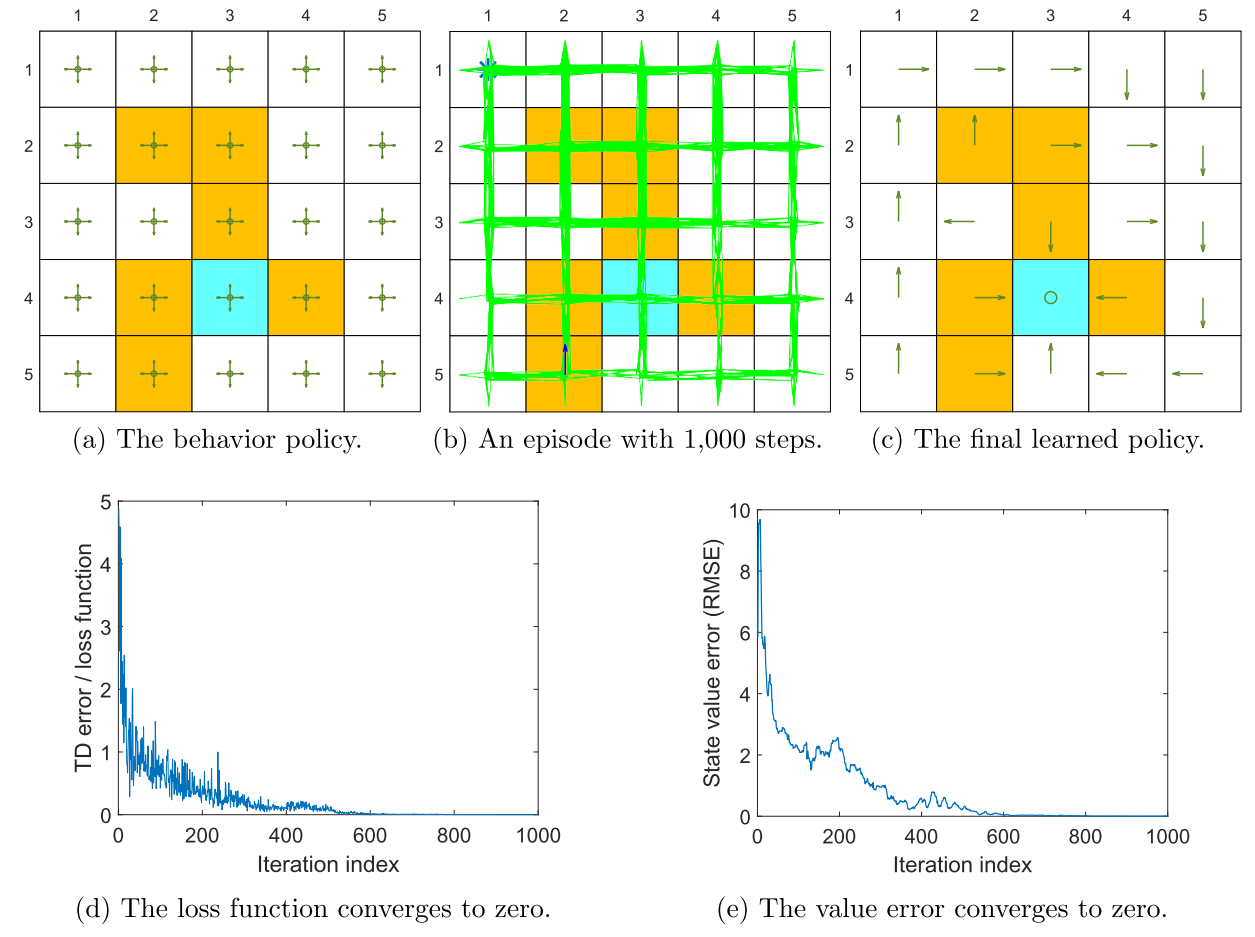
图\(8.11\):基于深度Q-learning的最优策略学习。其中 \(\gamma =0.9\),\(r_{\text{boundary}} = r_{\text{forbidden}} = -10\),且 \(r_{\text{target}} =1\)。批处理规模为100。
图\(8.12\):通过深度Q-learning实现的最优策略学习。其中,\(\gamma =0.9\),\(r_{\text{boundary}} = r_{\text{forbidden}} = -10\),且 \(r_{\text{target}} =1\)。批处理大小为50。