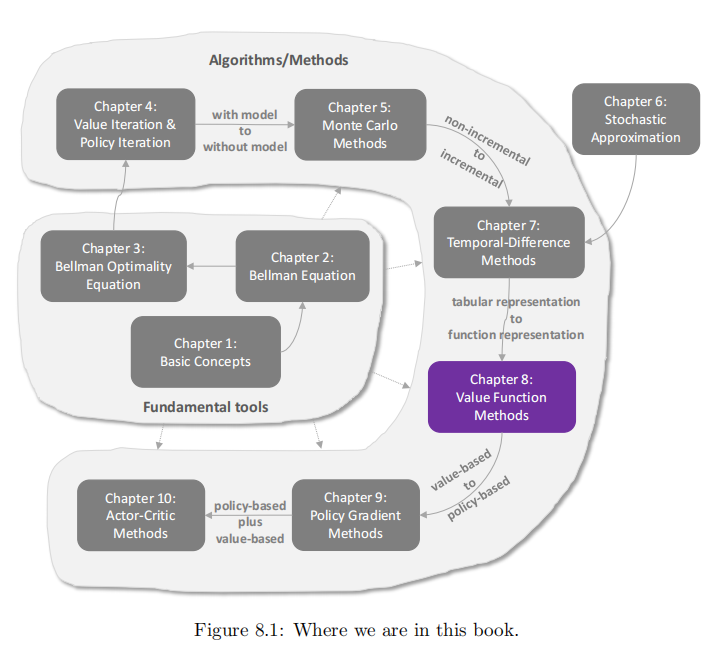
介绍 在本章中,我们将继续研究时序差分方法,但采用不同的方法来表示状态/行动值。到目前为止,本书内容均采用表格形式表示状态/行动值。虽然表格表示法直观易懂,但在处理大型状态空间或动作空间时效率不高。本章将引入函数来表示状态值/行动值,这种方法已成为当今强化学习的主流方法。神经网络作为很好的函数近似器,也是人工神经网络进入强化学习的原因。因此本章将用值来表示值,下一章将用函数来表示策略。 图\(8.1\): 本章在全书中的位置。