8.1-价值表示:从表格到函数
接下来通过一个例子来展示表格与函数方法的区别。
假设存在\(n\)个状态\(\{s_i\}_{i=1}^n\),其状态值为\(\{v_\pi(s_i)\}_{i=1}^n\),其中\(\pi\)为给定策略。令\(\{\hat{v}(s_i)\}_{i=1}^n\)表示对状态值的估计值。
如果采用表格法,这些估计值可以通过下表表示。这个表格在以数组或向量的形式存储在内存中。如果要检索或更新一个状态值,我们可以直接读取或者重写表格中对应的元素。
| 状态 | \(s_1\) | \(s_2\) | \(\cdots\) | \(s_n\) |
|---|---|---|---|---|
| 估计状态值 | \(\hat{v}(s_1)\) | \(\hat{v}(s_2)\) | \(\cdots\) | \(\hat{v}(s_n)\) |
注意到 \(\{(s_i, \hat{v}(s_i))\}_{i=1}^n\)是一组点,如图\(8.2\),这些点可以通过一条曲线进行拟合或近似。最简单的曲线是一条直线,其表达式为:
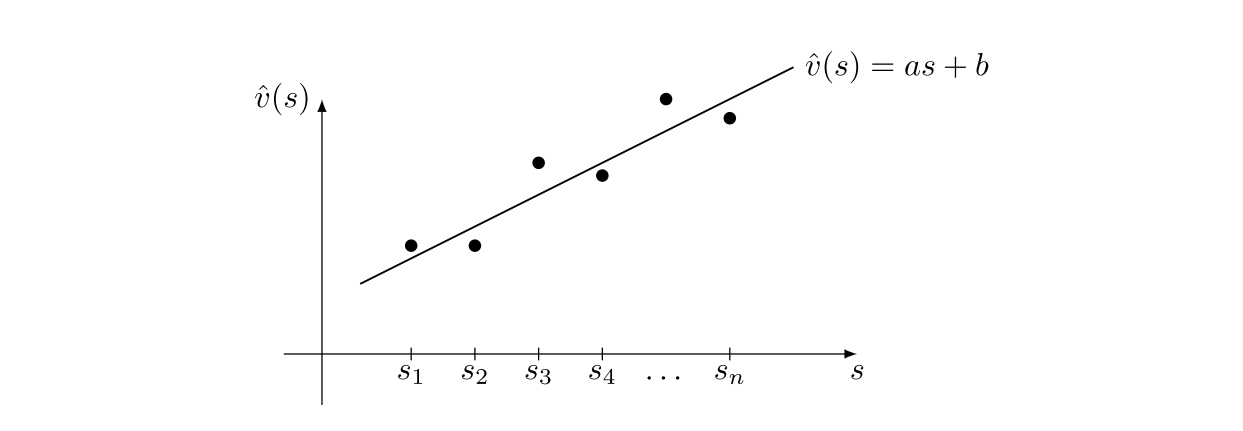
图\(8.2\):函数逼近方法示意图。\(x\)轴和\(y\)轴分别对应\(s\)与\(\hat{v}(s)\)。
其中\(\hat{v}(s, w)\)是用来近似\(v_\pi(s)\)的函数。该函数由状态\(s\)和参数向量\(w \in \mathbb{R}^2\)共同决定。\(\hat{v}(s, w)\)有时也被写成\(\hat{v}_w(s)\)。其中\(\phi(s) \in \mathbb{R}^2\)称为状态\(s\)的特征向量(feature vector)。
表格化方法与函数法之间的区别在于如何检索与更新值。
-
如何检索一个状态值:当表格形式呈现值时,若想要检索一个状态的值,可直接读取表中对应的元素。然而,当由函数描述值时,如果想要检索一个状态的值,我们需要将状态\(s\)输入到函数并计算函数值(图\(8.3\))。例如,以式\((8.1)\)为例,我们首先需要计算特征向量\(\phi(s)\),再计算\(\phi^T(s)w\)从而得到值。如果函数是用一个人工神经网络表示的,那么需要完成一次从输入到输出的前向传播,从而得到值。
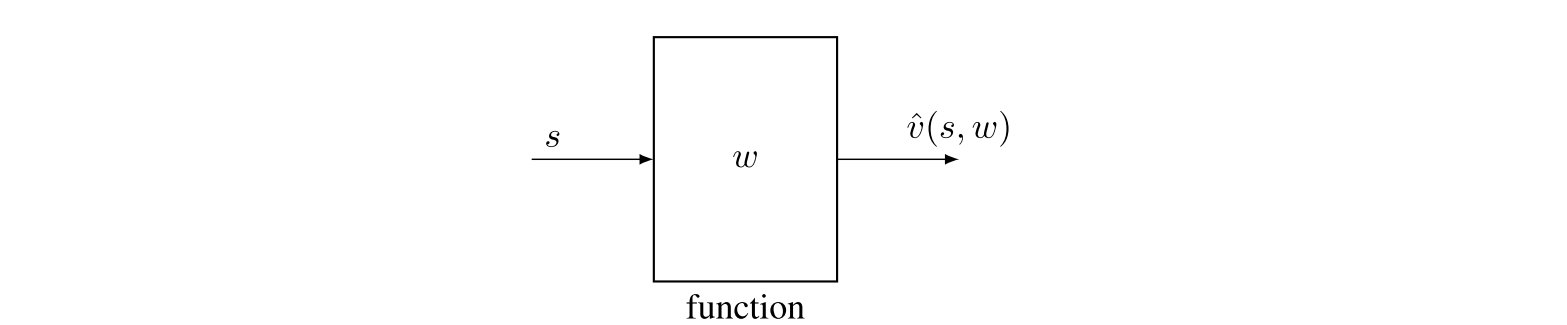
图\(8.3\):函数近似法求解\(s\)值过程的示意图。
函数法在存储方面更为高效,这源于其状态值的获取方式。具体而言,表格法需要存储\(n\)个状态值,而函数法仅需存储一个低维参数向量\(w\),因此存储效率可得到显著提升。然而这种优势是有代价的,函数可能无法准确描述所有状态值。如图\(8.2\)所示,真实的数据点并非严格落在一条直线上,这正是该方法被称为"函数近似"的原因。
从本质上看,当我们用低维向量(函数参数向量)表示高维向量(所有状态的值)时,必然会造成部分信息损失。因此,函数法是通过牺牲精度来提升存储效率的。
-
如何更新一个值:当用表格描述值时,如果想要更新一个值,我们可以直接重写表 格中对应的元素。然而,当值以函数表示时,更新一个值的方法则完全不同。具体而言,我们必须通过更新函数的参数\(w\)从而间接改变值。而不能像表格法那样直接修改某个状态的值。关于如何优化更新\(w\)以获取最佳状态值的方法,将在后文详细讨论。
得益于状态值的更新方式,函数近似方法的泛化能力优于表格法。具体来说,当使用表格法时,如果某一个状态被访问过,那么我们可以根据后续轨迹的回报来更新它的值。如果一个状态从来没有被访问过,它的值当然无法更新。然而,采用函数法时,我们需要通过更新权重向量\(w\)来更新一个状态的值,\(w\)的改变也会同时影响其他某些一些状态的值。因此,一个状态的经验样本可以泛化到改变其他一些状态的值。
上述分析如图\(8.4\)所示,其中包含三个状态\(\{s_1, s_2, s_3\}\)。
假设我们有一个关于状态\(s_3\)的经验样本,并想要更新\(\hat{v}(s_3)\)。若采用表格法,如图\(8.4(a)\)所示,我们只能更新\(\hat{v}(s_3)\),而不会改变\(\hat{v}(s_1)\)或\(\hat{v}(s_2)\)的值。但使用函数法时,如图\(8.4(b)\)所示,权重参数\(w\)的更新不仅会改变\(\hat{v}(s_3)\),还会连带影响\(\hat{v}(s_1)\)和\(\hat{v}(s_2)\)的估计值。因此,\(s_3\)的经验样本可以帮助我们估计其邻近状态的值。
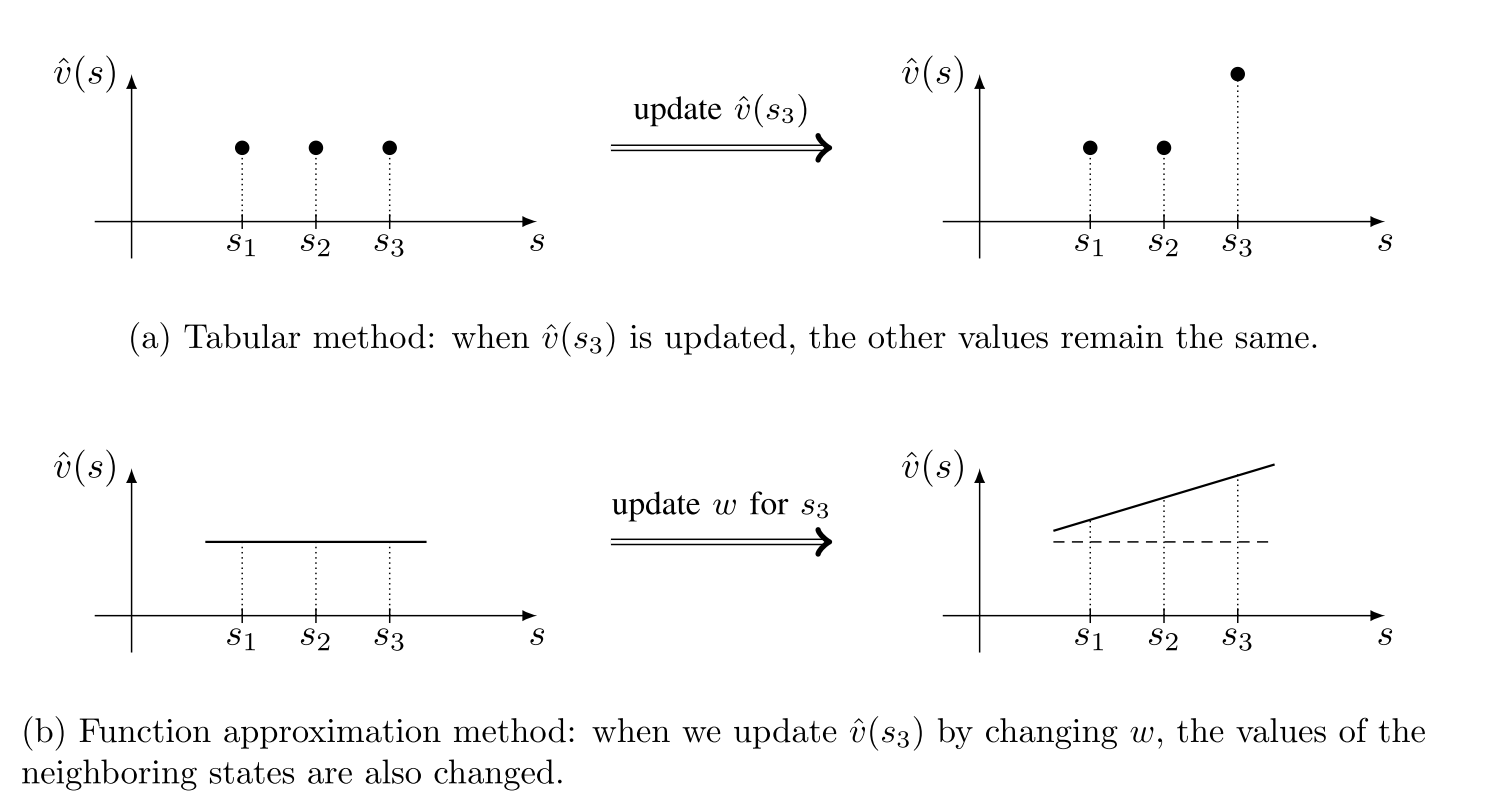
图\(8.4\):函数法和表格法如何更新值。
另外,我们也可以使用比直线更高阶的曲线来拟合,例如下面的二阶曲线:
随着曲线阶数的增加,拟合精度会相应提高,但参数向量的维度也会随之增加,从而需要更多的存储空间和计算资源。
注意到,\((8.1)\)或\((8.2)\)式中的\(\hat{v}(s, w)\)是关于\(w\)的线性函数(尽管对于\(s\)可能是非线性的)。这类方法称为线性函数近似(Linear function approximation),这也是最简单的值函数方法。要实现线性函数近似,我们需要选取合适的特征向量\(\phi(s)\)。例如,我们必须先决定是采用一阶直线还是二阶曲线来拟合。选择合适的特征向量并非易事,这需要我们对给定任务有较为丰富的先验知识:我们对任务了解得越深入,就可以选择越合适的特征向量。例如,我们如果已知图\(8.2\)中的数据点大致分布在一条直线上,我们可以用直线拟合这些数据点。然而,这类先验知识在实际中通常难以得到。若没有任何先验知识,常用的解决方案是采用人工神经网络作为非线性函数的近似器。
最后,如果使用线性函数来做拟合,那么如何寻找最优参数向量。若我们已知\(\{v_\pi(s_i)\}_{i=1}^n\),该问题可转化为一个简单的最小二乘问题。可以通过优化以下目标函数即可获得最优参数:
其中
可以验证,该最小二乘问题的最优解是
关于最小二乘问题的更多细节可参阅文献[47,第3.3节]和[48,第5.14节]。
综上所述,本节介绍的曲线拟合的例子直观地展示了值函数方法的基本思想。值函数方法的具体细节将从下节开始介绍。